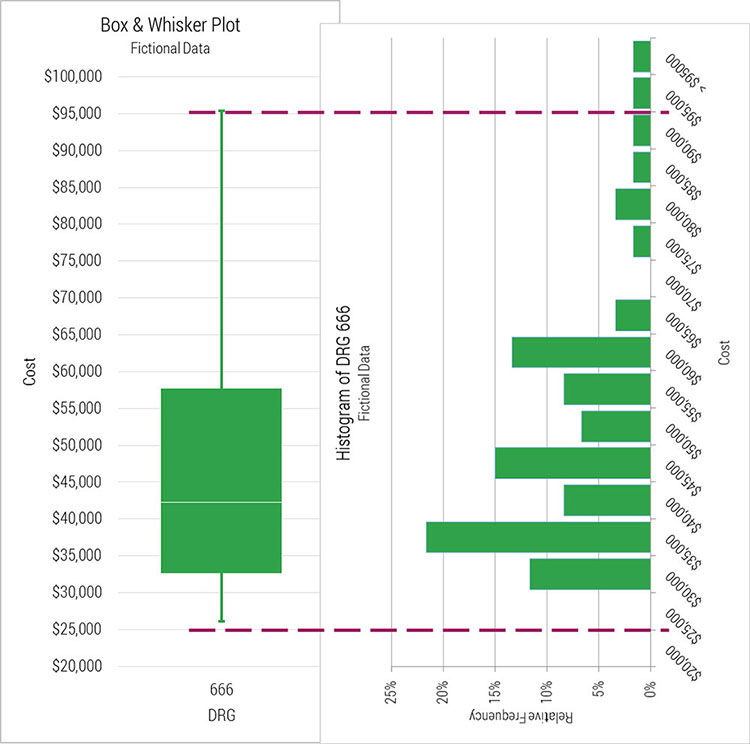
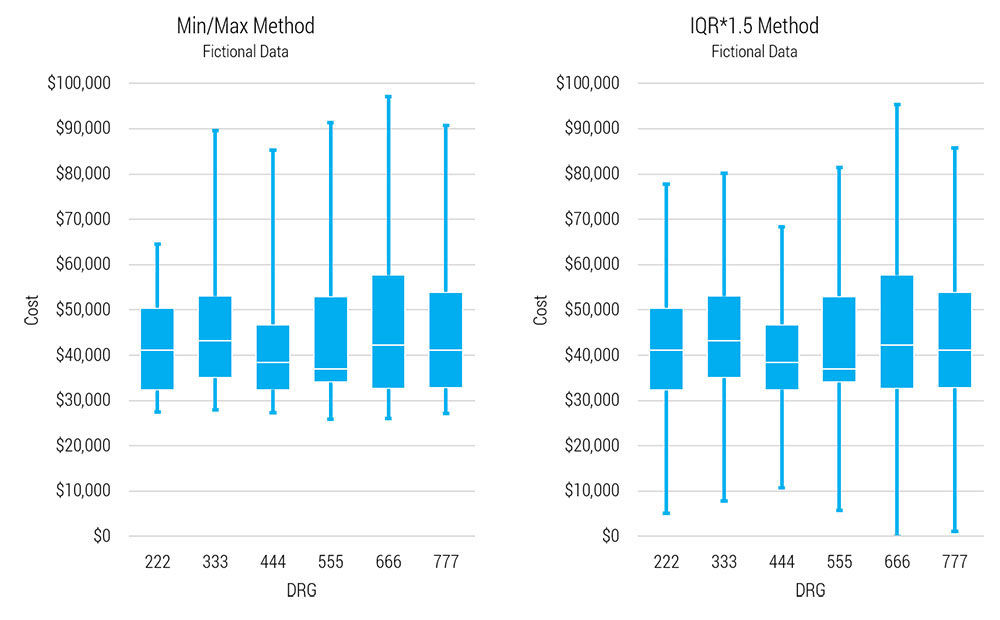
Notice the minimums (left graph) of the separate DRGs are tight ($25,895 - $27,868. Range = $1,972). The IQR*1.5 method (right) is a gross misrepresentation of the lower quartiles, but in the upper quartiles it’s the maximums which are misrepresenting the data; five of six DRGs’ maximums are outliers. That is, in the upper quartile, the IQR*1.5 method is better. Those complex formulas select the best representation in each case.
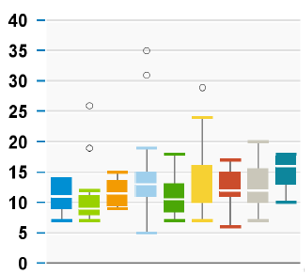 The default method in BOE is even better. It expands on this logic to set the upper whisker at the minimum datum that’s less than (75th %ile + IQR*1.5) and then it shows any higher data as outliers. And it works in reverse in the lower whisker. Here’s an example I pulled from a BOE scorecard. Those little circles are outlier cases. The groups in this case are calendar quarters allowing the reader to look for trends over time, but because they’re box & whisker plots, the reader can also study distributions of any single quarter.
The default method in BOE is even better. It expands on this logic to set the upper whisker at the minimum datum that’s less than (75th %ile + IQR*1.5) and then it shows any higher data as outliers. And it works in reverse in the lower whisker. Here’s an example I pulled from a BOE scorecard. Those little circles are outlier cases. The groups in this case are calendar quarters allowing the reader to look for trends over time, but because they’re box & whisker plots, the reader can also study distributions of any single quarter.
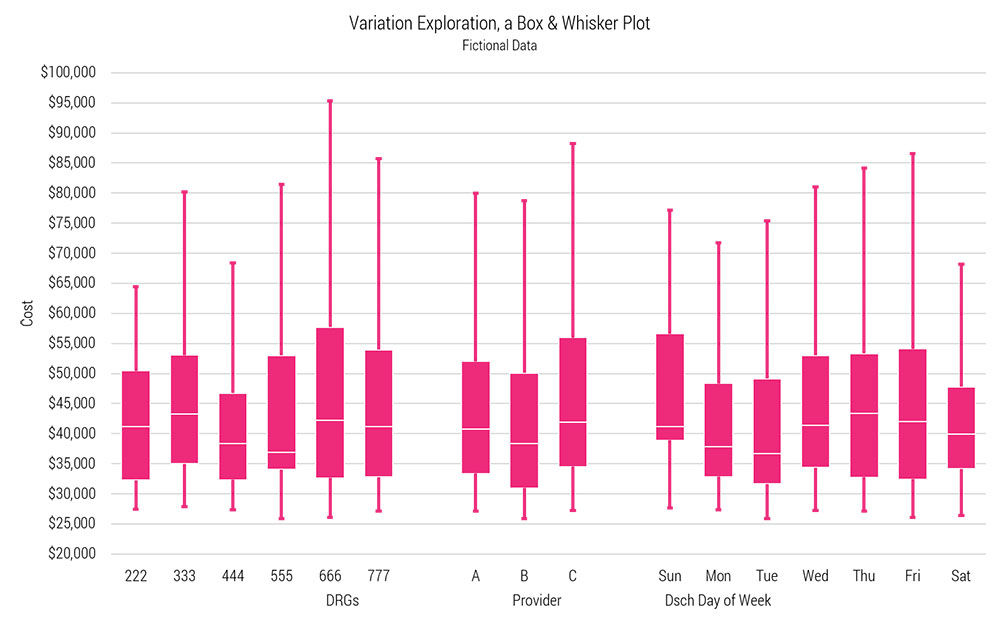
Last week we examined just the DRG group. If you took this analysis one step further you could compare the variation among the six DRGs without depending on point estimates like standard deviation. Box & whisker plots were born for this.
These three plots, side-by-side and set to the same scale, help visualize variation within and between groups.